FileGPT.dev
Private document vault: upload files and get instant, cited answers. RAG-powered chat with hybrid search, conversation memory, and Supabase-backed vectors.
A privacy-first alternative to general-purpose AI tools for sensitive internal documents.
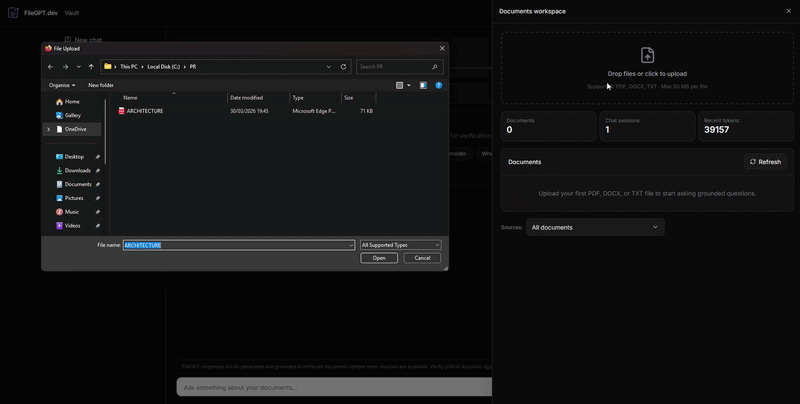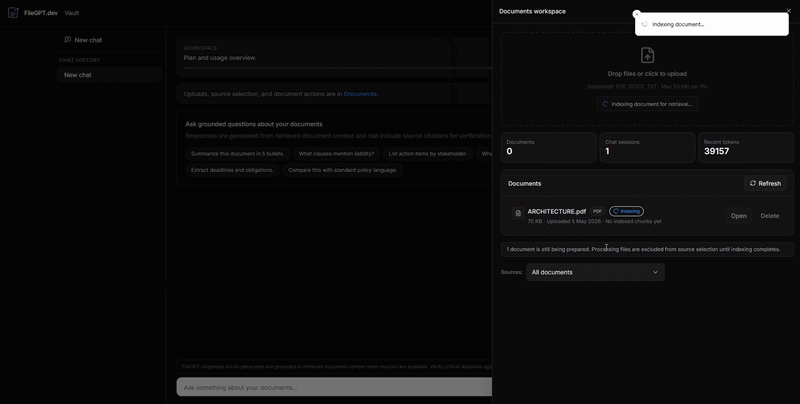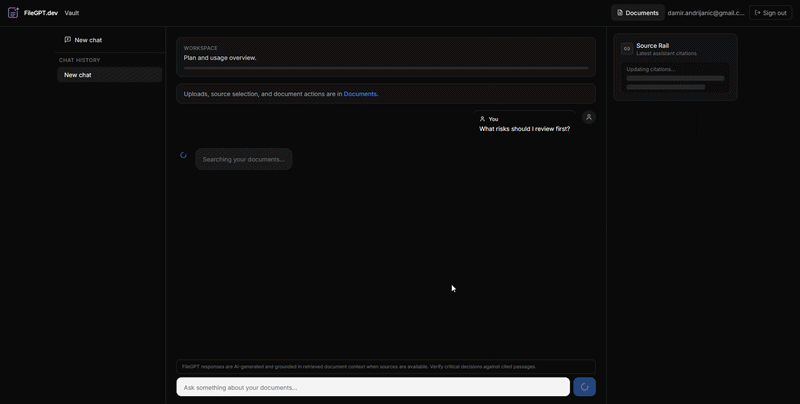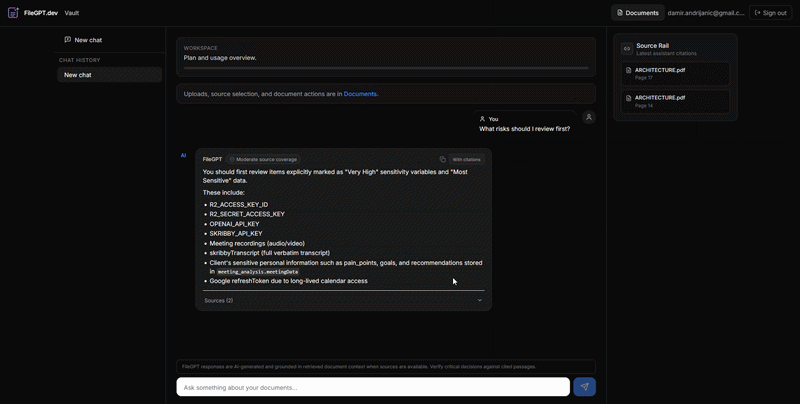
FileGPT.dev is a private document vault that turns internal files into a citation-first knowledge experience. Users upload PDFs and office documents, then chat against the vault with streaming answers and explicit source badges. With authentication enabled, Supabase isolates each tenant’s data end to end. The ingestion pipeline extracts, chunks, and embeds content into Postgres via the pgvector extension; retrieval combines vector search with safeguards and observability (audit logs and usage events). The codebase evolved from an earlier internal iteration (reflected in some migration filenames); the shipped product is branded exclusively as FileGPT.dev.
Architecture
Features
- Citation-first chat — streaming answers with explicit source badges like [Source: file.pdf, Page N] rendered as source chips.
- Guarded hybrid retrieval — Gemini embeddings with vector search in Supabase (pgvector), plus keyword-style fallback when needed for exact-term recall.
- Conversation memory — condenses recent messages into a standalone query before retrieval so follow-ups keep context.
- Ingestion with lifecycle tracking — documents move PROCESSING → COMPLETE/FAILED with chunk counts; supports PDF/TXT/MD/DOCX/XLSX extraction.
- Enterprise controls — optional auth + multi-tenancy, RBAC (VIEWER restrictions), rate limiting, audit logs, usage events, and API access patterns suitable for production.
Enterprise requirements (checklist)
- Data privacy: documents aren’t used to train public models; tenant data stays isolated in Supabase with scoped access.
- Source attribution: every answer includes the originating document (and page when available).
- Authentication + access control: optional sign-in, role restrictions (Admin/Editor/Viewer).
- Auditability: audit logs capture who queried what and when; usage events support cost monitoring.
- Integration: programmatic upload and query flows via authenticated API routes.
Security & operations
- Multi-tenancy: Row-level data scoping in Postgres and private object storage prevent cross-tenant access.
- Guardrails: rate limiting to control abuse and spend; query-embedding cache reduces redundant embedding calls.
- Deployment-ready: Vercel-friendly Next.js 15 setup with serverless API routes and environment-based configuration.
- Observability: structured logging hooks, tracing integration, and persisted usage events for tuning and budgets.
Tech stack
- Next.js 15 (App Router), TypeScript, Tailwind CSS — UI and routes
- Vercel AI SDK — streaming chat and AI primitives
- Google Gemini — chat, condensation, and gemini-embedding-001 vectors (768 dimensions, aligned with pgvector)
- Supabase — Auth, private file storage, PostgreSQL with pgvector for chunk storage and similarity search
Document ingestion pipeline
- Create a document record (PROCESSING), ingest from storage, then mark COMPLETE (with chunk counts) or FAILED.
- Extract content by type: PDF (pdf-parse + optional Vision summary for smaller PDFs), DOCX (Mammoth), XLSX (sheet → CSV text), TXT/MD (UTF-8).
- Chunking: fixed-size windows or semantic sentence-aware chunking depending on configuration.
- Embed with Gemini, store vectors in pgvector with metadata (file name, document id, user scope, snippets) for retrieval.